散列表是最有用的基本数据结构之一,它的用途广泛。
散列表的内部机制有:实现、冲突和散列函数。学习这些会帮助你理解如何分析散列表的性能。
散列函数
散列函数“将输入映射到数字”。
散列函数需要满足的要求:
- 它必须是一致的。每次输入相同内容,得到的映射值必须相同;
- 它应尽可能将不同的输入映射到不同的数字。
可以结合使用散列函数和数组创建一种被称为散列表 (hash table)的数据结构,散列表使用散列函数来确定元素的存储位置。
散列表适合用于:
- 模拟映射关系;
- 防止重复;
- 缓存/记住数据,以免服务器再通过处理来生成它们。
冲突
散列函数将两个不同内容映射到了相同的位置上,这时就会发生冲突。
处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。
经验教训:
散列函数很重要 。最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。
如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好 ,这些链表就不会很长!
性能
比较一下散列表同数组和链表的运行时间:
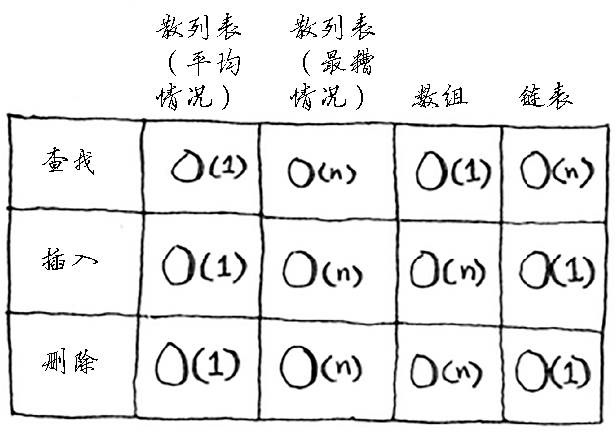
在最糟情况下,散列表所有操作的运行时间都为O (n )——线性时间。
避开最糟情况至关重要。为此,需要避免冲突。而要避免冲突,需要有:
- 较低的填装因子;
- 良好的散列函数。
填装因子
散列表的填装因子=散列表包含的元素数/位置总数。
填装因子越低,发生冲突的可能性越小,散列表的性能越高。
一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。
良好的散列函数
良好的散列函数让数组中的值呈均匀分布。
糟糕的散列函数让值扎堆,导致大量的冲突。
可以研究一下SHA函数(本书最后一章做了简要的介绍)。你可将它用作散列函数。
小结
- 你可以结合散列函数和数组来创建散列表。
- 散列表适合用于模拟映射关系。
- 散列表非常适合用于防止重复。
- 散列表可用于缓存数据(例如,在Web服务器上)。
- 冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。
- 散列表的查找、插入和删除速度都非常快。
- 一旦填装因子超过0.7,就该调整散列表的长度。