K最近邻算法
K最近邻算法简称KNN,该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
推荐系统
假如要为用户创建一个电影推荐系统,可以使用K最近邻算法。
用户在特征空间的位置取决于其对电影的喜好,喜好相似的用户距离较近。假如要为A推荐电影,可以找出五位与他最接近的用户,他们喜欢的电影很可能A也喜欢。
抽取特征
在挑选合适的特征方面,没有放之四海皆准的法则,必须考虑到各种需要考虑的因素。
用户注册时,可以要求他们指出对各种电影的喜欢程度。这样,对于每位用户,都将获得一组数字,这可以作为用户的特征。
然后使用毕达哥拉斯公式来计算两个用户的距离:
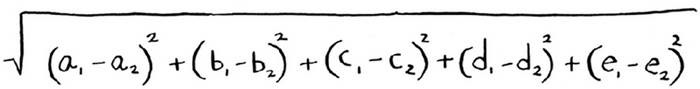
在实际工作中,经常使用余弦相似度来计算两个用户的距离。
回归
假设要预测用户A会给某电影打多少分,只要计算出和A最相似的5个人对该电影打分的平均值就可以了,这个过程就是回归。
机器学习
OCR
如何自动识别出这个数字是什么呢?可使用KNN。
- 浏览大量的数字图像,将这些数字的特征提取出来。
- 遇到新图像时,你提取该图像的特征,再找出它最近的邻居都是谁!
OCR的第一步是查看大量的数字图像并提取特征,这被称为训练(training)。大多数机器学习算法都包含训练的步骤。
创建垃圾邮件过滤器
垃圾邮件过滤器使用一种简单算法——朴素贝叶斯分类器 (Naive Bayes classifier)
- 首先使用一些数据对这个分类器进行训练。
- 假设你收到一封主题为“collect your million dollars now!”的邮件,研究这个句子中的每个单词,看看它在垃圾邮件中出现的概率是多少。
预测股票市场
由于涉及的变数太多,使用机器学习来预测股票市场的涨跌很难,几乎是不可能完成的任务。
小结
- KNN用于分类和回归,需要考虑最近的邻居。
- 分类就是编组。
- 回归就是预测结果(如数字)。
- 特征抽取意味着将物品(如水果或用户)转换为一系列可比较的数字。
- 能否挑选合适的特征事关KNN算法的成败。